4月8日,《美国科学院院报》(PNAS)发表了一篇文章,在国际学术圈与中国舆论场内,又掀起了些许波澜。有些媒体和自媒体在报道时,将其视为病毒溯源的重要证据;与之相反,学术界却对其有不少批评意见。
PNAS论文好眼熟
这篇题为《Phylogenetic network analysis of SARS-CoV-2 genomes》的文章,与之前被部分人引为“溯源证据”的两篇论文有些相似之处:即西双版纳热带植物园(版纳所)的《Decoding the evolution and transmissions of the novel pneumonia coronavirus (SARS-CoV-2) using whole genomic data》,以及多位中国科学家共同撰写的《On the origin and continuing evolution of SARS-CoV-2》。
看英文名字也许你还不熟悉,不过一提坊间流传的说法——“五毒说”和“S型、L型”,大概就知道了吧。
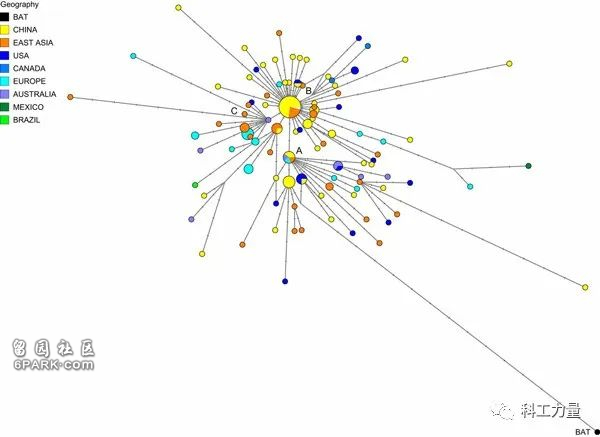
PNAS论文的配图

被错误归纳为“五毒说”的版纳所文章的配图
《On the origin and continuing evolution of SARS-CoV-2》的配图
三篇论文都是根据早期样本的基因差异建立网络,看着相似一点都不奇怪。只不过版纳所和PNAS的主要归类,都是依据网络的结构,而S型、L型的归类则是根据两个互相关联的位点——8782与28144,PNAS论文的网络中,A类与B类分支也正是据这两个位点形成的。
一些媒体与自媒体对文章的解读也相似,认为其中某一个类群更为“古老”,进而认为“古老”类群在哪个地方多,那个地方就可能是起源地。
遗憾的是,“古老”类型的推断并不成立。PNAS论文与另两篇论文一样,都用蝙蝠冠状病毒序列RaTG13作为参考。我在之前的文章中就指出过:
蝙蝠冠状病毒序列RaTG13与新冠病毒虽然接近,但要用来确定“祖先”还差得太远。RaTG13与新冠病毒大约有4%的差异,即1000个以上的核苷酸,而新冠病毒的差异也就十几个,根本不能确定RaTG13哪些地方与真正的“祖先型”接近。
大牛Andrew Rambaut一连喷了好几条推特,以下只是其中的三条:
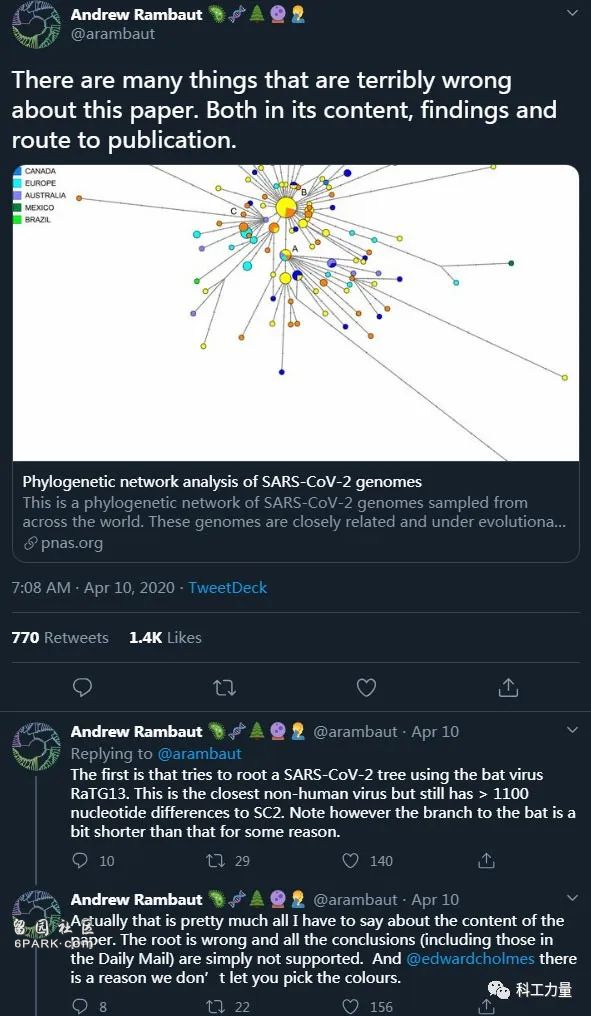
这篇文章有许多地方都犯了大错,包括内容、发现结论和发布的途径。
首先是试图用蝙蝠病毒RaTG13给新冠树定根。这是最接近的非人病毒,但和新冠仍有超过1100个核苷酸的差异。然而请注意,由于某些原因,图上连到蝙蝠的分支比1100个核苷酸短些。
实际上,关于内容我想说的就这么多,根定错了,所有的结论(包括《每日邮报》里的那些)都得不到支持了。
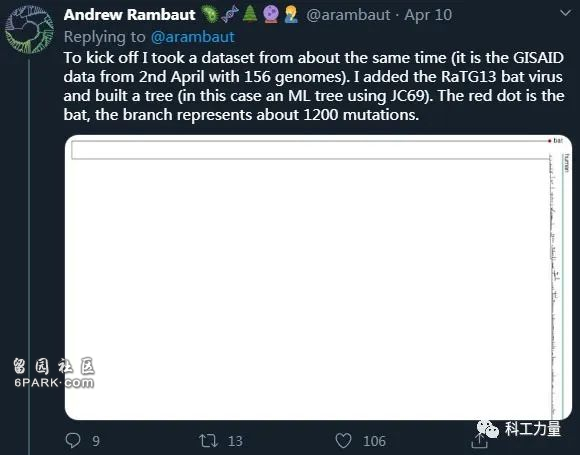
Andrew有一条推特尤为重要,可以直观看到用RaTG13为什么错了。他用差不多时间段的156个基因组,建了一棵树(JC69是Jukes和Cantor 1969年建立的模型),图中右侧往下一串密密麻麻的,就是新冠的分支,而上面一个孤零零的红点,则是RaTG13,用相距这么远的玩意儿定根不是搞笑吗?
在方法上,PNAS论文还广受诟病的一点是,这么晚还在用仅仅160个样本,如果是2月的文章,还说得过去,可现在还发这样的文章,迟钝得简直像IE浏览器。
版纳所等文章提前上网进一步放大了PNAS论文的滞后感,但即使忽略这一点,PNAS论文确实也没有带来多少新东西。但后者甚至没有提及这两篇已有颇多讨论的类似文章。
不过,我在这里要为论文作者说两句公道话,现在固然已经公布了大量样本基因,但一般而言,它们对溯源并无帮助。我在最近的文章里写过:
后面采集的样本其实主要是在把“树”做大,对挖“深”根部没什么帮助……最多也就是整体判断下,“大树”有没有什么“异常”。
因此,作者没有用上后来的几百上千个数据,并不是什么过错。
但早期数据的弊病,作者也没有克服。我曾说明:
中国一开始对疾病的判断限定与海鲜市场有关,美国等一开始限定与中国有关,从避免恐慌、避免挤兑医疗资源的角度来说,是可以理解的,但给溯源带来了更多困难。
现有的早期样本的比对研究,都无法摆脱这个困扰。而且样本少的情况下,稍有缺失,就会有很大影响。
早期样本的数量需要增加,但如果只是在原有数据中,稍微放宽选取的时间,是没有用的;如果新测了一些早期样本,但这些样本是按照旧原则确定的,同样也没用。简单地说,测来测去都是市场相关、武汉相关或中国相关的病例,那么溯源问题几乎不会有突破性的进展。
怎么做才有用呢?对于这样一个存在大量轻症且可自愈的疾病,需要广泛寻找更早的疑似病例检测。
可见,在这样的情况下,论文作者用的数据不多,不是什么大问题,但在数据没有根本性突破的时候,确实做了无用功。
PNAS论文将古生物学已有不少应用的系统发生网络,应用到病毒进化上,算是一点小小的创新。但版纳所的文章用得更早,连软件都是一样的NETWORK(当然具体工具还是有所不同)。
系统发生网络,和一般的系统树相比,一个比较明显的特征,就是样本会出现在节点上,而树的样本出现在末端。系统发生网络在病毒进化中也许可以更好地反映出重组信息。
学术研究会有路径依赖,但我想病毒学家此前没有积极应用系统发生网络的原因,可能不只是这样。样本间两两比较地构建系统树,也许更方便将流行病学调查的数据纳入模型,而这些对病毒学研究是至关重要的。
因此,PNAS论文的这些小创新,很难得到喝彩。
这里插播点学术八卦。学术圈很快注意到,这个古生物学方法的迁移很可能来自作者之一、古人类学者Colin Renfrew,而另外三个是Forster一家……
这篇文章呢,正巧是Colin Renfrew以美国科学院院士的身份在自家院报上“贡献”(contribute)的。有人嘲讽说,其实夸师娘的文章都能“贡献”到院报上,我觉得有点夸张了;但“贡献”文章有相当一部分质量不高,这样的说法并不夸张。
另外,《2018 年中国科学院文献情报中心期刊分区表》把PNAS降为了2区,只把Nature和Science留在了1区。
更早几年,有人在学术论坛上说:“PNAS是美国科学院院刊,在上面发文章,美国科学院院士有一定的特权(一年能contribute 4篇),由此导致一些不规范和不公平在所难免。现在国内一些课题组有钱,常请一些美国科学院院士过来交流访问,然后通过这些院士在PNAS上发文章,接着拿着这些文章当作重大成果去申请经费,其中有些文章的水平连专业学科二类杂志的水平都达不到。特权的存在是这么多年来PNAS常被人诟病以及在一些学科领域显得非主流的一个重要原因。”
与国内的这层关系,这是不是PNAS降区的主要原因呢?这只能问中科院了。
八卦到此结束,回到正题。
媒体的乌龙
前面的讨论或许还可归为学术范畴,绝大部分媒体、自媒体工作者“无能为力”,但以下关键性误读还是难辞其咎的:论文作者压根就没有从某一“古老类群”中某地类型的多寡,去谈论起源地。
对于致病微生物来说,某些分支变大,基因多样性变高,不能单单凭此证明来源地是哪里,我之前文章里举过一个例子:
病毒在A地传播,但传播的人数有限,传到B地后,疫情失控,B地的病毒虽然晚,复制的机会却比留在A地的病毒多得多,那么复制出错的机会也就更多,基因多样性也就上去了。
PNAS论文作者当然不会犯这样的错误。我们可以比对论文原文与流传的说法,看看误读到底是怎么发生的。
作者在摘要里说的是:A类与C类有相当多比例在东亚以外地区被发现。相反,B类是东亚最常见的类型,B类的原始类型似乎没有传到东亚以外,直到最初的突变产生B类衍生型后才传出去。这一现象指向奠基者效应或东亚以外对B类原始型在免疫上或环境上的抗性。

在正文里说的是:根据同义突变T29095C,A类可以明显分为两个子簇。在T突变子簇里,四个中国个体(来自华南沿海省份广东)携带原始类型,三个日本和两个美国病人与之不同,有一些突变差异。据报告,这些美国病人都在推测是爆发源头的武汉有居住史。
C突变子簇里有相对长的突变分支,包括五个武汉个体,其中两个显示在原始节点里;还包括8个来自中国和邻国的东亚人。然而值得注意的是,C突变子簇里几乎一半(33个里面的15个)的类型,在东亚以外被发现,主要在美国和澳大利亚。

一些媒体、自媒体说A类里“更多”“主要”的是美国、澳大利亚,实在离谱。仔细看原文就能发现,作者讲到美澳时,只是提了其中一个子簇,而东亚以外的样本,甚至还不到这个子簇的一半。
我都怀疑作者是不是写错了,在那张圆圈大小代表的样本数没有具体标注、T子簇与C子簇也没有标注的烂图上,根本看不清楚啊,一下子还真数不出15/33。
我干脆下了数据表格看,给中国的标上红色,总共12个,包括台湾、香港各1,给美国的标上蓝色,给澳大利亚标上紫色,给欧洲标上绿色。作者原来没写错,非东亚还真是15/33,其中美国7个,澳大利亚5个,两者相加比C子簇总数的1/3,也就是11个多1个。
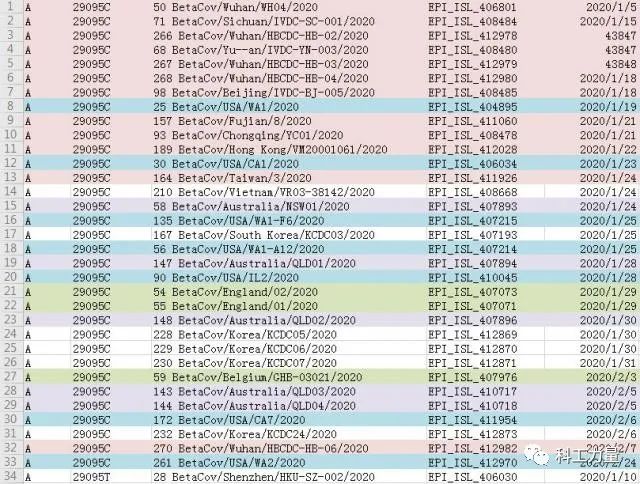
所以,美澳的“主要”是指A类中的C子簇中的非东亚样本中的“主要”。可一些媒体和自媒体,竟然直接把中间内容全部砍掉了。
此外,从上面两段引文里还可以看到,作者指出A类T子簇、C子簇的原始类型,中国都有份。不管A类是否真的“古老”,从这篇文章中,也无法得出令人满意的关于起源的确切结论。
早在探讨版纳所论文时,就有不少学者指出,美国和广东最早的病例,虽然因为错误的定根而被误认为更“原始”,但都有武汉旅行史,而且发病时间晚于武汉早期病例。所以,很难说是从那里传到武汉的。
但我们也不能断言,就一定是武汉传过去的,新发现一批早期样本,就有可能产生颠覆性的结果。
这可以充分说明,如我前面所言,早期样本缺失带来了多么大的困境。
总体而言,这篇论文和先前的类似论文一样,由于方法上的缺陷,在学术圈“收获”了一堆批评,而媒体则由于误读,又闹了一次乌龙。
科学的结论依然是,根据现有证据,不知道新冠病毒确切的起源。
政治与科学
有的朋友也许会问,新冠病毒起源问题已经政治化了,怎么能就科学谈科学呢?
然而,科学问题是基础,如何做出政治决策是要建立在科学基础之上的。舆论战就是战争,你可以把各种论据比作弹药,科学家和科普工作者就是弹药专家。他们有义务告诉指战员们,哪些弹药威力巨大,哪些弹药可能是哑弹,哪些弹药甚至可能会炸膛。至于在了解弹药性能后,指战员如何使用,那就是政治范畴了。
你也可以把一篇论文,视作舆论战的一处战场,科学家和科普工作者的任务就是勘察战地,必须报告指战员:哪些地形有利,可以大作文章;哪些地形不利,不妨避战;还有哪些地形可能依然处于迷雾中,情况不明,需要慎重对待。
但是地形不利,地形不明,或许也可以“兵行险着”,也可能会取得战果,这些也是政治决策者的工作。
反过来说,如果科学家和科普工作者,出于某种政治目的,刻意错误解读论文,也就是给出了错误“情报”。这样不仅没有干好自己的本职工作,反而有越俎代庖之嫌。
也有的朋友或许会说,那这些情报完全可以写内参啊,为什么要在公共领域里发布呢?
这也许要归结为新媒体时代的特殊性。如今的舆论战有官方和民间两种力量。“民间武装”可以当好一个免疫系统,与癌细胞(境内谣言)和病原体(境外输入谣言)作斗争。现在,极少数“民间武装”还有走出国门、反驳谣言的可能。
“民间武装”的这些行动,同样需要“情报支持”。然而,他们不受官方节制,与官方不通情报,如果科学家和科普工作者只通过内部渠道向官方提供信息,这些“民间武装”就得不到可靠的“情报”。
因此,在公共平台上,还是有必要坚持科普,坚持实事求是。至于“民间武装”收到情报后,如何决策,如何行动,那是他们的权利。
也有人担心,这些“情报”不会被别人利用吗?当然有可能,但因此而闭塞信息,实在不符合互联网精神,也没有更好的办法,向这么广大的“民间武装”提供情报。
而且,目前没有证据证明任何一个国家是病毒源头,这些“情报”并不能被敌人用作实锤。有些美国人倒是想“兵行险着”,妄言源头,妄用名称,已经吃了从WHO、中国到美国国内反对派的很多批评。
最后不得不提的是,政治化也许已经彻底阻绝了找到源头的可能。如前所述,要找源头,最需要的是突破早期诊断标准的限制,各国都应该去“偷坟掘墓”,但政治化后,恐怕谁都不想去做“吃力不讨好”的事。
政治化真真切切地阻碍了“人类卫生健康共同体”的构建,这一共同体事关每个人的福祉,谁有理由不谴责这样的政治化呢?


